Appearance
TypeScript 4.0
可变参元组类型
在 JavaScript 中有一个函数concat,它接受两个数组或元组并将它们连接在一起构成一个新数组。
js
function concat(arr1, arr2) {
return [...arr1, ...arr2];
}再假设有一个tail函数,它接受一个数组或元组并返回除首个元素外的所有元素。
js
function tail(arg) {
const [_, ...result] = arg;
return result;
}那么,我们如何在 TypeScript 中为这两个函数添加类型?
在旧版本的 TypeScript 中,对于concat函数我们能做的是编写一些函数重载签名。
ts
function concat(arr1: [], arr2: []): [];
function concat<A>(arr1: [A], arr2: []): [A];
function concat<A, B>(arr1: [A, B], arr2: []): [A, B];
function concat<A, B, C>(arr1: [A, B, C], arr2: []): [A, B, C];
function concat<A, B, C, D>(arr1: [A, B, C, D], arr2: []): [A, B, C, D];
function concat<A, B, C, D, E>(arr1: [A, B, C, D, E], arr2: []): [A, B, C, D, E];
function concat<A, B, C, D, E, F>(arr1: [A, B, C, D, E, F], arr2: []): [A, B, C, D, E, F];)在保持第二个数组为空的情况下,我们已经编写了七个重载签名。 接下来,让我们为arr2添加一个参数。
ts
function concat<A2>(arr1: [], arr2: [A2]): [A2];
function concat<A1, A2>(arr1: [A1], arr2: [A2]): [A1, A2];
function concat<A1, B1, A2>(arr1: [A1, B1], arr2: [A2]): [A1, B1, A2];
function concat<A1, B1, C1, A2>(
arr1: [A1, B1, C1],
arr2: [A2]
): [A1, B1, C1, A2];
function concat<A1, B1, C1, D1, A2>(
arr1: [A1, B1, C1, D1],
arr2: [A2]
): [A1, B1, C1, D1, A2];
function concat<A1, B1, C1, D1, E1, A2>(
arr1: [A1, B1, C1, D1, E1],
arr2: [A2]
): [A1, B1, C1, D1, E1, A2];
function concat<A1, B1, C1, D1, E1, F1, A2>(
arr1: [A1, B1, C1, D1, E1, F1],
arr2: [A2]
): [A1, B1, C1, D1, E1, F1, A2];这已经开始变得不合理了。 不巧的是,在给tail函数添加类型时也会遇到同样的问题。
在受尽了“重载的折磨”后,它依然没有完全解决我们的问题。 它只能针对已编写的重载给出正确的类型。 如果我们想要处理所有情况,则还需要提供一个如下的重载:
ts
function concat<T, U>(arr1: T[], arr2: U[]): Array<T | U>;但是这个重载签名没有反映出输入的长度,以及元组元素的顺序。
TypeScript 4.0 带来了两项基础改动,还伴随着类型推断的改善,因此我们能够方便地添加类型。
第一个改动是展开元组类型的语法支持泛型。 这就是说,我们能够表示在元组和数组上的高阶操作,尽管我们不清楚它们的具体类型。 在实例化泛型展开时 当在这类元组上进行泛型展开实例化(或者使用实际类型参数进行替换)时,它们能够产生另一组数组和元组类型。
例如,我们可以像下面这样给tail函数添加类型,避免了“重载的折磨”。
ts
function tail<T extends any[]>(arr: readonly [any, ...T]) {
const [_ignored, ...rest] = arr;
return rest;
}
const myTuple = [1, 2, 3, 4] as const;
const myArray = ['hello', 'world'];
const r1 = tail(myTuple);
// [2, 3, 4]
const r2 = tail([...myTuple, ...myArray] as const);
// [2, 3, 4, ...string[]]第二个改动是,剩余元素可以出现在元组中的任意位置上 - 不只是末尾位置!
ts
type Strings = [string, string];
type Numbers = [number, number];
type StrStrNumNumBool = [...Strings, ...Numbers, boolean];
// [string, string, number, number, boolean]在以前,TypeScript 会像下面这样产生一个错误:
txt
剩余元素必须出现在元组类型的末尾。但是在 TypeScript 4.0 中放开了这个限制。
注意,如果展开一个长度未知的类型,那么后面的所有元素都将被纳入到剩余元素类型。
ts
type Strings = [string, string];
type Numbers = number[];
type Unbounded = [...Strings, ...Numbers, boolean];
// [string, string, ...(number | boolean)[]]结合使用这两种行为,我们能够为concat函数编写一个良好的类型签名:
ts
type Arr = readonly any[];
function concat<T extends Arr, U extends Arr>(arr1: T, arr2: U): [...T, ...U] {
return [...arr1, ...arr2];
}虽然这个签名仍有点长,但是我们不再需要像重载那样重复多次,并且对于任何数组或元组它都能够给出期望的类型。
该功能本身已经足够好了,但是它的强大更体现在一些复杂的场景中。 例如,考虑有一个支持部分参数应用的函数partialCall。 partialCall接受一个函数(例如叫作f),以及函数f需要的一些初始参数。 它返回一个新的函数,该函数接受f需要的额外参数,并最终以初始参数和额外参数来调用f。
js
function partialCall(f, ...headArgs) {
return (...tailArgs) => f(...headArgs, ...tailArgs);
}TypeScript 4.0 改进了剩余参数和剩余元组元素的类型推断,因此我们可以为这种使用场景添加类型。
ts
type Arr = readonly unknown[];
function partialCall<T extends Arr, U extends Arr, R>(
f: (...args: [...T, ...U]) => R,
...headArgs: T
) {
return (...tailArgs: U) => f(...headArgs, ...tailArgs);
}此例中,partialCall知道能够接受哪些初始参数,并返回一个函数,它能够正确地选择接受或拒绝额外的参数。
ts
// @errors: 2345 2554 2554 2345
type Arr = readonly unknown[];
function partialCall<T extends Arr, U extends Arr, R>(
f: (...args: [...T, ...U]) => R,
...headArgs: T
) {
return (...tailArgs: U) => f(...headArgs, ...tailArgs);
}
// ---cut---
const foo = (x: string, y: number, z: boolean) => {};
const f1 = partialCall(foo, 100);
// ~~~
// Argument of type 'number' is not assignable to parameter of type 'string'.
const f2 = partialCall(foo, 'hello', 100, true, 'oops');
// ~~~~~~
// Expected 4 arguments, but got 5.(2554)
// This works!
const f3 = partialCall(foo, 'hello');
// (y: number, z: boolean) => void
// What can we do with f3 now?
// Works!
f3(123, true);
f3();
f3(123, 'hello');可变参元组类型支持了许多新的激动人心的模式,尤其是函数组合。 我们期望能够通过它来为 JavaScript 内置的bind函数进行更好的类型检查。 还有一些其它的类型推断改进以及模式引入进来,如果你想了解更多,请参考PR。
标签元组元素
改进元组类型和参数列表使用体验的重要性在于它允许我们为 JavaScript 中惯用的方法添加强类型验证 - 例如对参数列表进行切片而后传递给其它函数。 这里至关重要的一点是我们可以使用元组类型作为剩余参数类型。
例如,下面的函数使用元组类型作为剩余参数:
ts
function foo(...args: [string, number]): void {
// ...
}它与下面的函数基本没有区别:
ts
function foo(arg0: string, arg1: number): void {
// ...
}对于foo函数的任意调用者:
ts
function foo(arg0: string, arg1: number): void {
// ...
}
foo('hello', 42);
foo('hello', 42, true); // Expected 2 arguments, but got 3.
foo('hello'); // Expected 2 arguments, but got 1.但是,如果从代码可读性的角度来看,就能够看出两者之间的差别。 在第一个例子中,参数的第一个元素和第二个元素都没有参数名。 虽然这不影响类型检查,但是元组中元素位置上缺乏标签令它们难以使用 - 很难表达出代码的意图。
这就是为什么 TypeScript 4.0 中的元组可以提供标签。
ts
type Range = [start: number, end: number];为了加强参数列表和元组类型之间的联系,剩余元素和可选元素的语法采用了参数列表的语法。
ts
type Foo = [first: number, second?: string, ...rest: any[]];在使用标签元组时有一些规则要遵守。 其一是,如果一个元组元素使用了标签,那么所有元组元素必须都使用标签。
ts
type Bar = [first: string, number];
// Tuple members must all have names or all not have names.(5084)元组标签名不影响解构变量名,它们不必相同。 元组标签仅用于文档和工具目的。
ts
function foo(x: [first: string, second: number]) {
// ...
// 注意:不需要命名为'first'和'second'
const [a, b] = x;
a;
// string
b;
// number
}总的来说,标签元组对于元组和参数列表模式以及实现类型安全的重载时是很便利的。 实际上,在代码编辑器中 TypeScript 会尽可能地将它们显示为重载。
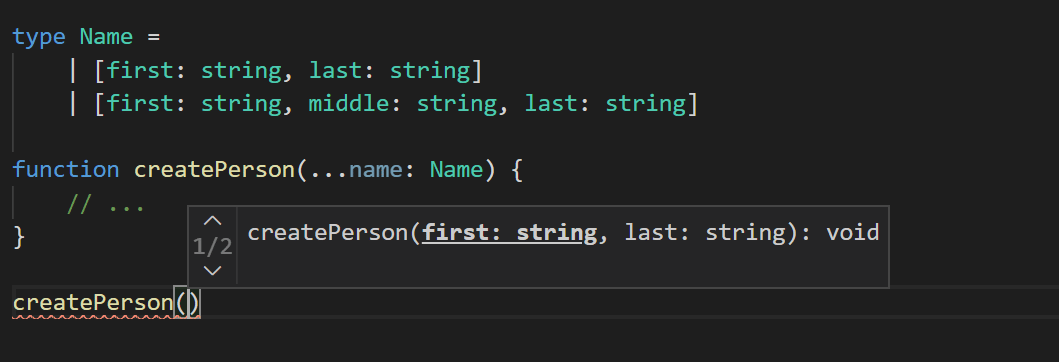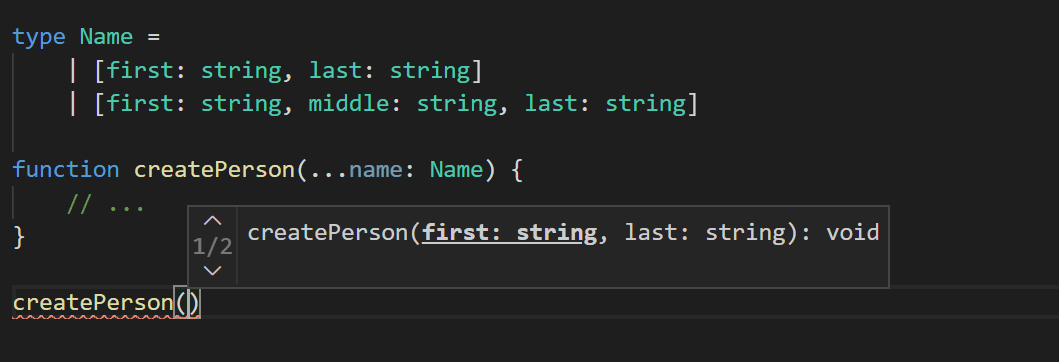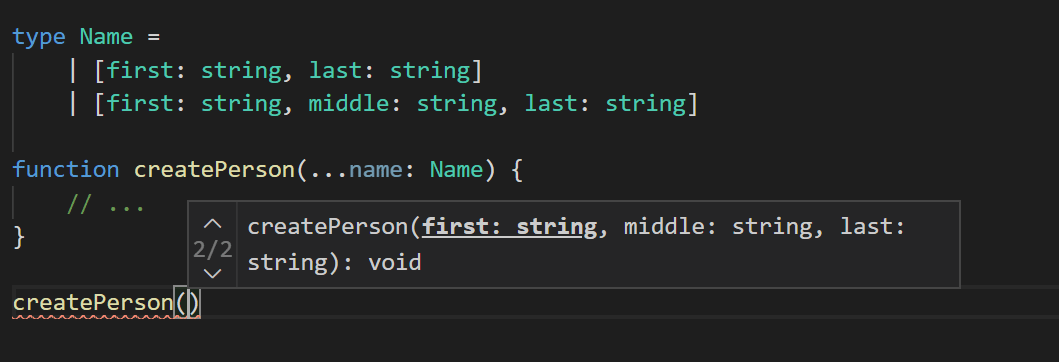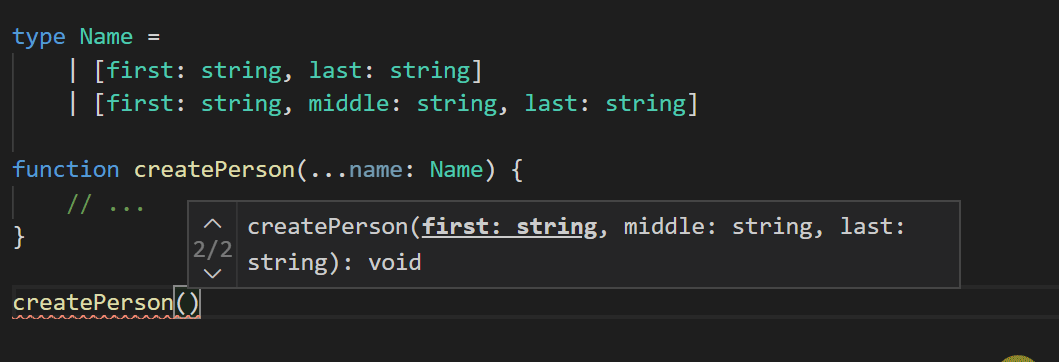
更多详情请参考PT。
从构造函数中推断类属性
在 TypeScript 4.0 中,当启用了noImplicitAny时,编译器能够根据基于控制流的分析来确定类中属性的类型
ts
class Square {
// 在旧版本中,以下两个属性均为any类型
area; // number
sideLength; // number
constructor(sideLength: number) {
this.sideLength = sideLength;
this.area = sideLength ** 2;
}
}如果没有在构造函数中的所有代码执行路径上为实例成员进行赋值,那么该属性会被认为可能为undefined类型。
ts
class Square {
sideLength; // number | undefined
constructor(sideLength: number) {
if (Math.random()) {
this.sideLength = sideLength;
}
}
get area() {
return this.sideLength ** 2;
// ~~~~~~~~~~~~~~~
// 对象可能为'undefined'
}
}如果你清楚地知道属性类型(例如,类中存在类似于initialize的初始化方法),你仍需要明确地使用类型注解来指定类型,以及需要使用确切赋值断言(!)如果你启用了strictPropertyInitialization模式。
ts
class Square {
// 确切赋值断言
// v
sideLength!: number;
// ^^^^^^^^
// 类型注解
constructor(sideLength: number) {
this.initialize(sideLength);
}
initialize(sideLength: number) {
this.sideLength = sideLength;
}
get area() {
return this.sideLength ** 2;
}
}更多详情请参考PR.
断路赋值运算符
JavaScript 以及其它很多编程语言支持一些复合赋值运算符。 复合赋值运算符作用于两个操作数,并将运算结果赋值给左操作数。 你从前可能见到过以下代码:
ts
// 加
// a = a + b
a += b;
// 减
// a = a - b
a -= b;
// 乘
// a = a * b
a *= b;
// 除
// a = a / b
a /= b;
// 幂
// a = a ** b
a **= b;
// 左移位
// a = a << b
a <<= b;JavaScript 中的许多运算符都具有一个对应的赋值运算符! 目前为止,有三个值得注意的例外:逻辑与(&&),逻辑或(||)和逻辑空值合并(??)。
这就是为什么 TypeScript 4.0 支持了一个 ECMAScript 的新特性,增加了三个新的赋值运算符&&=,||=和??=。
这三个运算符可以用于替换以下代码:
ts
a = a && b;
a = a || b;
a = a ?? b;或者相似的if语句
ts
// could be 'a ||= b'
if (!a) {
a = b;
}还有以下的惰性初始化值的例子:
ts
let values: string[];
(values ?? (values = [])).push('hello');
// After
(values ??= []).push('hello');少数情况下当你使用带有副作用的存取器时,值得注意的是这些运算符只在必要时才执行赋值操作。 也就是说,不仅是运算符右操作数会“短路”,整个赋值操作也会“短路”
ts
obj.prop ||= foo();
// roughly equivalent to either of the following
obj.prop || (obj.prop = foo());
if (!obj.prop) {
obj.prop = foo();
}尝试运行这个例子来查看与 始终执行赋值间的差别。
ts
const obj = {
get prop() {
console.log('getter has run');
// Replace me!
return Math.random() < 0.5;
},
set prop(_val: boolean) {
console.log('setter has run');
},
};
function foo() {
console.log('right side evaluated');
return true;
}
console.log('This one always runs the setter');
obj.prop = obj.prop || foo();
console.log('This one *sometimes* runs the setter');
obj.prop ||= foo();非常感谢社区成员Wenlu Wang为该功能的付出!
更多详情请参考PR. 你还可以查看该特性的 TC39 提案.
catch语句中的unknown类型
在 TypeScript 的早期版本中,catch语句中的捕获变量总为any类型。 这意味着你可以在捕获变量上执行任意的操作。
ts
try {
// Do some work
} catch (x) {
// x 类型为 'any'
console.log(x.message);
console.log(x.toUpperCase());
x++;
x.yadda.yadda.yadda();
}上述代码可能导致错误处理语句中产生了更多的错误,因此该行为是不合理的。 因为捕获变量默认为any类型,所以它不是类型安全的,你可以在上面执行非法操作。
TypeScript 4.0 允许将catch语句中的捕获变量类型声明为unknown类型。 unknown类型比any类型更加安全,因为它要求在使用之前必须进行类型检查。
ts
try {
// ...
} catch (e: unknown) {
// Can't access values on unknowns
console.log(e.toUpperCase());
if (typeof e === 'string') {
// We've narrowed 'e' down to the type 'string'.
console.log(e.toUpperCase());
}
}由于catch语句捕获变量的类型不会被默认地改变成unknown类型,因此我们考虑在未来添加一个新的--strict标记来有选择性地引入该行为。 目前,我们可以通过使用代码静态检查工具来强制catch捕获变量使用了明确的类型注解: any或: unknown。
更多详情请参考PR.
自定义 JSX 工厂
在使用 JSX 时,fragment类型的 JSX 元素允许返回多个子元素。 当 TypeScript 刚开始实现 fragments 时,我们不太清楚其它代码库该如何使用它们。 最近越来越多的库开始使用 JSX 并支持与 fragments 结构相似的 API。
在 TypeScript 4.0 中,用户可以使用jsxFragmentFactory选项来自定义 fragment 工厂。
例如,下例的tsconfig.json文件告诉 TypeScript 使用与 React 兼容的方式来转换 JSX,但使用h来代替React.createElement工厂,同时使用Fragment来代替React.Fragment。
json5
{
compilerOptions: {
target: 'esnext',
module: 'commonjs',
jsx: 'react',
jsxFactory: 'h',
jsxFragmentFactory: 'Fragment',
},
}如果针对每个文件具有不同的 JSX 工厂,你可以使用新的/** @jsxFrag */编译指令注释。 示例:
tsx
// 注意:这些编译指令注释必须使用JSDoc风格,否则不起作用
/** @jsx h */
/** @jsxFrag Fragment */
import { h, Fragment } from 'preact';
export const Header = (
<>
<h1>Welcome</h1>
</>
);上述代码会转换为如下的 JavaScript
tsx
// 注意:这些编译指令注释必须使用JSDoc风格,否则不起作用
/** @jsx h */
/** @jsxFrag Fragment */
import { h, Fragment } from 'preact';
export const Header = h(Fragment, null, h('h1', null, 'Welcome'));非常感谢社区成员Noj Vek为该特性的付出。
更多详情请参考PR
对启用了--noEmitOnError的`build 模式进行速度优化
在以前,当启用了--noEmitOnError编译选项时,如果在--incremental构建模式下的前一次构建出错了,那么接下来的构建会很慢。 这是因为当启用了--noEmitOnError时,前一次失败构建的信息不会被缓存到.tsbuildinfo文件中。
TypeScript 4.0 对此做出了一些改变,极大地提升了这种情况下的编译速度,改善了应用--build模式的场景(包含--incremental和--noEmitOnError)。
更多详情请参考PR。
--incremental和--noEmit
TypeScript 4.0 允许同时使用--incremental和--noEmit。 这在之前是不允许的,因为--incremental需要生成.tsbuildinfo文件; 然而,提供更快地增量构建对所有用户来讲都是十分重要的。
更多详情请参考PR。
编辑器改进
TypeScript 编译器不但支持在大部分编辑器中编写 TypeScript 代码,还支持着在 Visual Studio 系列的编辑器中编写 JavaScript 代码。 因此,我们主要工作之一是改善编辑器支持 - 这也是程序员花费了大量时间的地方。
针对不同的编辑器,在使用 TypeScript/JavaScript 的新功能时可能会有所区别,但是
- Visual Studio Code 支持选择不同的 TypeScript 版本。或者,安装JavaScript/TypeScript Nightly Extension插件来使用最新的版本。
- Visual Studio 2017/2019 提供了 SDK 安装包,以及MSBuild 安装包。
- Sublime Text 3 支持选择不同的 TypeScript 版本
这里是支持 TypeScript 的编辑器列表,到这里查看你喜爱的编译器是否支持最新版本的 TypeScript。
转换为可选链
可选链是一个较新的大家喜爱的特性。 TypeScript 4.0 带来了一个新的重构工具来转换常见的代码模式,以利用可选链和空值合并!

注意,虽然该项重构不能完美地捕获真实情况(由于 JavaScript 中较复杂的真值/假值关系),但是我们坚信它能够适用于大多数使用场景,尤其是在 TypeScript 清楚地知道代码类型信息的时候。
更多详情请参考PR。
/** @deprecated */支持
TypeScript 现在能够识别代码中的/** @deprecated *JSDoc 注释,并对编辑器提供支持。 该信息会显示在自动补全列表中以及建议诊断信息,编辑器可以特殊处理它。 在类似于 VS Code 的编辑器中,废弃的值会显示为删除线,例如like this。
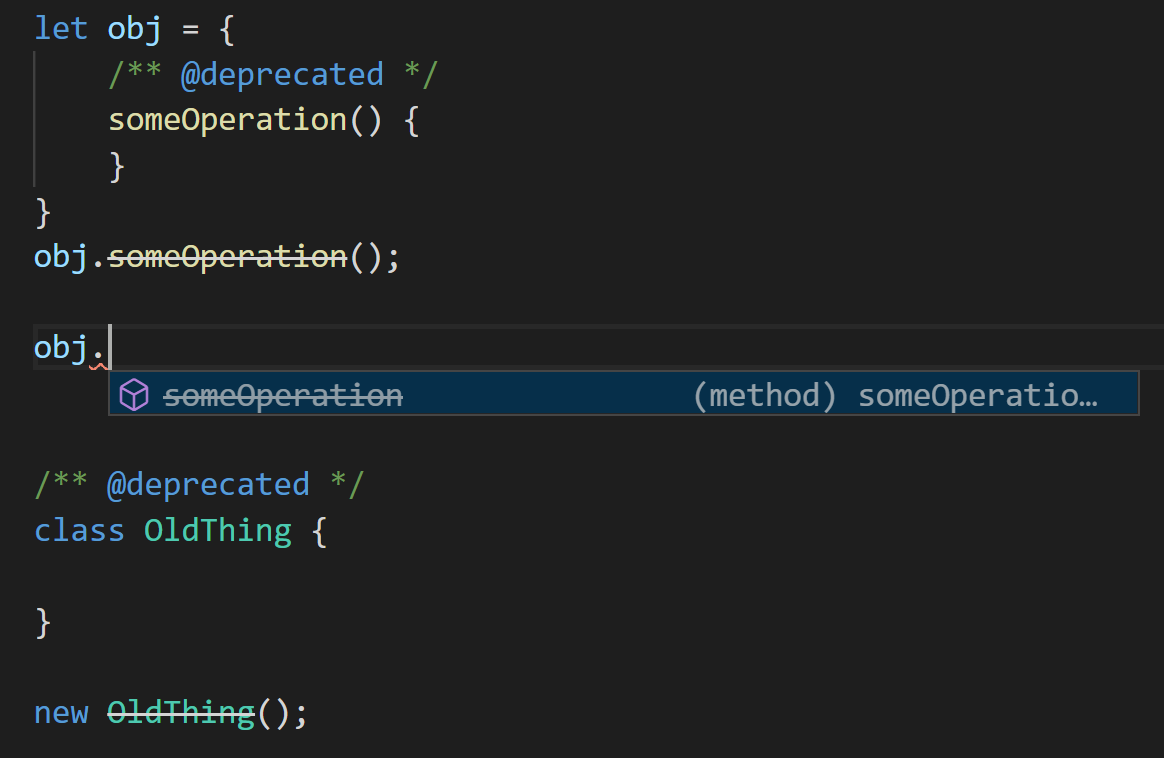
感谢Wenlu Wang为该特性的付出。 更多详情请参考PR。
启动时的局部语义模式
我们从用户反馈得知在启动一个大的工程时需要很长的时间。 罪魁祸首是一个叫作程序构造的处理过程。 该处理是从一系列根文件开始解析并查找它们的依赖,然后再解析依赖,然后再解析依赖的依赖,以此类推。 你的工程越大,你等待的时间就越长,在这之前你不能使用编辑器的诸如“跳转到定义”等功能。
这就是为什么我们要提供一个新的编辑器模式,在语言服务被完全加载之前提供局部编辑体验。 这里的主要想法是,编辑器可以运行一个轻量级的局部语言服务,它只关注编辑器当前打开的文件。
很难准确地形容能够获得多大的提升,但听说在 Visual Studio Code 项目中,以前需要等待20 秒到 1 分钟的时间来完全加载语言服务。 做为对比,*新的局部语义模式看起来能够将上述时间减少到几秒钟。* 示例,从下面的视频中,你可以看到左侧的 TypeScript 3.9 与右侧的 TypeScript 4.0 的对比。
当在编辑器中打开一个大型的代码仓库时,TypeScript 3.9 根本无法提供代码补全以及信息提示。 反过来,安装了 TypeScript 4.0 的编辑器能够在当前文件上立即提供丰富的编辑体验,尽管后台仍然在加载整个工程。
目前,唯一一个支持该模块的编辑器是Visual Studio Code,并且在Visual Studio Code Insiders版本中还带来了一些体验上的优化。 我们发现该特性在用户体验和功能性上仍有优化空间,我们总结了一个优化列表。 我们也期待你的使用反馈。
更多详情请参考原始的提议,功能实现的 PR,以及后续的跟踪帖.
更智能的自动导入
自动导入是个特别好的功能,它让编码更加容易;然而,每一次自动导入不好用的时候,它就会导致一部分用户流失。 一个特殊的问题是,自动导入对于使用 TypeScript 编写的依赖不好用 - 也就是说,用户必须在工程中的某处明确地编写一个导入语句。
那么为什么自动导入在@types包上是好用的,但是对于自己编写的代码却不好用? 这表明自动导入功能只适用于工程中已经引入的包。 因为 TypeScript 会自动地将node_modules/@types下面的包引入进工程,那些包才会被自动导入。 另一方面,其它的包会被排除,因为遍历node_modules下所有的包相当费时。
这就导致了在自动导入一个刚刚安装完但还没有开始使用的包时具有相当差的体验。
TypeScript 4.0 对编辑器环境进行了一点小改动,它会自动引入你的工程下的package.json文件中dependencies(和peerDependencies)字段里列出的包。 这些引入的包只用于改进自动导入功能,它们对类型检查等其它功能没有任何影响。 这使得自动导入功能对于项目中所有带有类型的依赖项都是可用的,同时不必遍历node_modules。
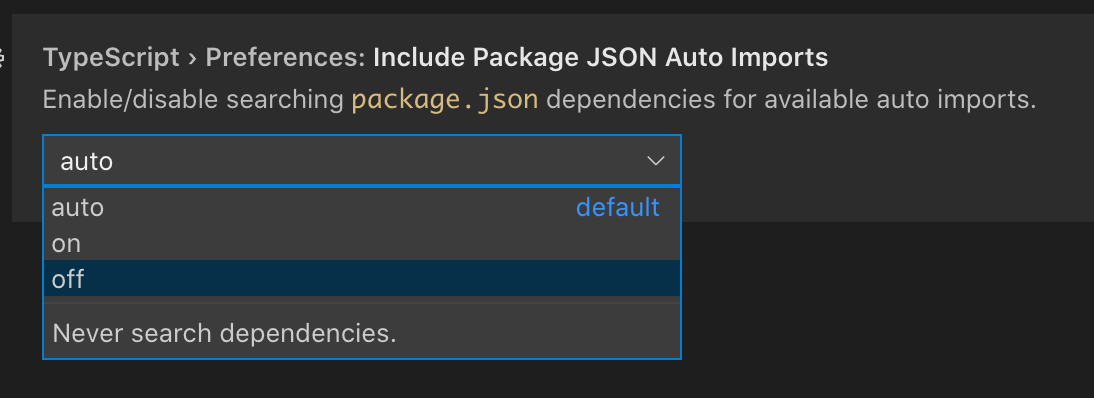
少数情况下,若在package.json中列出了多于 10 个未导入的带有类型的依赖,那么该功能会被自动禁用以避免过慢的工程加载。 若想要强制启用该功能,或完全禁用该功能,则需要配置你的编辑器。 针对 Visual Studio Code,对应到“Include Package JSON Auto Imports”配置(或者typescript.preferences.includePackageJsonAutoImports配置)。
 For more details, you can see the proposal issue along with the implementing pull request.
For more details, you can see the proposal issue along with the implementing pull request.
我们的新网站
最近,我们重写了TypeScript 官网并且已经发布!
我们在这里介绍了关于新网站的一些信息;但仍期望用户给予更多的反馈! 如果你有问题或建议,请到这里提交 Issue。